In the ever-evolving landscape of artificial intelligence, the incorporation of domain-specific knowledge into language models (LLMs) is not just a lofty goal—it’s a mission-critical aspect of model performance. This is where fine-tuning and Retriever-Reader (RAG) come into the picture, two powerful approaches with distinct methodologies for imbuing models with domain-specific prowess. As the Director of AI Research at a tech startup, investing in the right approach to empower language models with knowledge is a debate that rages on in our weekly strategy meetings. In this piece, I dissect the benefits and trade-offs of both methods, aiming to help data scientists, AI enthusiasts, and tech professionals make informed decisions regarding the enhancement of LLMs.
Introduction
The modern data scientist wields the power to curate a model’s understanding to an unprecedented degree. Incorporating domain knowledge has become less of an afterthought and more of the central piece to the puzzle of AI applications. As established models like GPT-3 demonstrate extraordinary capabilities, the question of specialized knowledge arises. Both fine-tuning and RAG have stepped forward as capable candidates for augmenting language models, offering different paths to the same destination.
Fine-tuning: Leveraging Existing Models
Fine-tuning involves starting with a pre-trained model and updating its weights using labeled examples from within the target domain. The rationale is simple: rather than reinventing the wheel, one can build upon the wealth of knowledge already stored within established models.
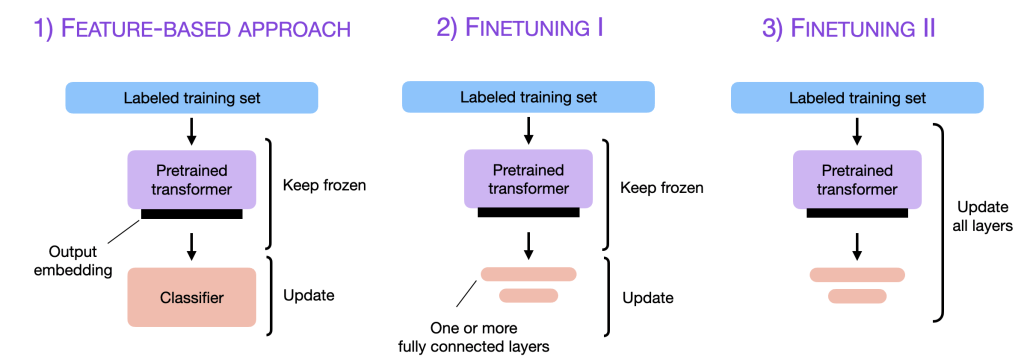
The Fine-tuning Approach in Depth
Fine-tuning has gained popularity due to its relatively lower resource consumption compared to training from scratch. Pre-trained models come with an inherent understanding of language and are adept at various natural language processing (NLP) tasks. By fine-tuning these models, often with a smaller, domain-specific dataset, we can specialize the general model to fit particular needs.
Benefits of Fine-tuning
- Faster Deployment: Leveraging an existing model allows for a quicker setup, reducing the time from development to deployment significantly.
- Capitalizing on Pre-trained Weights: The pre-training phase is costly in terms of computation and time. Fine-tuning capitalizes on this investment, using pre-trained weights as a head start for domain tasks.
- Leveraging Pre-Trained Models: Pre-trained models are increasingly sophisticated and capture various nuances of human language.
Examples of Successful Applications
The medical field, for instance, has seen strides with fine-tuned models specializing in entity recognition, question answering, and summarization tasks. In patient data analysis, these models can parse through vast amounts of unstructured text, extracting relevant information with precision.
RAG: Incorporating Explicit Knowledge
RAG, on the other hand, is a more recently introduced framework designed to incorporate external knowledge sources into the inference process. It aims to enhance the rationality and awareness of AI systems by allowing them to query reference materials as part of their preliminary thinking.
The RAG Framework in Depth
The RAG framework consists of two components: a retriever and a reader. The retriever uses a query to extract relevant passages from a knowledge source, and the reader processes these passages to find an answer or provide context.
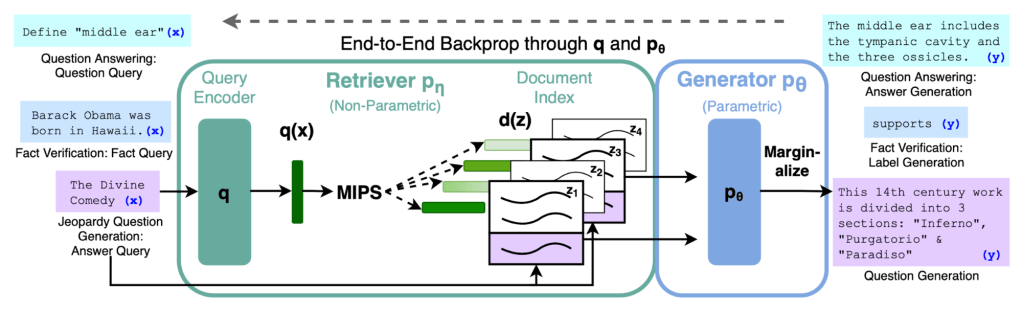
Advantages of RAG
- Handling Out-of-Domain Queries: RAG is capable of tackling a broader set of tasks, not just those within the dataset scope, by referring to the internet or other massive knowledge bases.
- Interpretability: The retriever component offers insights into the knowledge basis of the model’s decisions, essential for accountability and trust in AI systems.
Real-World Use Cases
In legal research, for example, RAG models can sift through laws, cases, and precedents to provide up-to-date advice, cross-referencing information as legal landscapes shift. As such, the legal domain provides a fertile ground for RAG models to shine, reshaping how we approach legal queries and research.
Strengths and Weaknesses of Fine-tuning
Fine-tuning isn’t without its downsides. While it excels in many facets, particularly speed and leveraging existing models, it does come with concerns over model performance in unique domains.
Discussion of the Strengths
Fine-tuned models often achieve better performance on in-domain tasks, as they’ve been trained to recognize and respond to specific patterns and language nuances within the domain.
Analysis of the Weaknesses
Fine-tuned models can be sensitive to the distribution and quality of the training data. Overfitting, a common problem, may occur, leading to less generalizable models. Moreover, fine-tuning can inadvertently strip away some of the broader knowledge captured in the pre-training phase.
Strengths and Weaknesses of RAG
RAG’s ability to query large knowledge bases is a distinct advantage but not without its own set of challenges.
Examination of the Strengths
RAG models offer improved interpretability, particularly through the retriever’s explicit referencing of the source of its decisions. They also enjoy the benefit of not being overly specialized to a specific domain, serving as a more flexible solution.
Analysis of the Weaknesses
However, RAG’s computational requirements are significant. Each query necessitates running through a retrieval system, which can be a bottleneck in terms of the model’s scalability. There’s also the potential for errors in retrieving and parsing large external datasets.
Trade-offs and Considerations
When facing a decision between fine-tuning and RAG, it’s critical to assess the nuances of each approach and how they align with the project’s objectives and constraints.
Comparison of the Two Approaches
- Performance: Fine-tuned models often outperform RAG models on in-domain tasks. However, RAG’s ability to call upon external knowledge can provide a richer context and improve overall understanding.
- Flexibility: RAG models are inherently more flexible, handling out-of-domain queries with ease. Fine-tuned models may struggle with tasks beyond their initial scope.
- Resource Requirements: Fine-tuning generally requires fewer resources, both in terms of infrastructure and data. RAG, with its need for knowledge bases and retrieval systems, tends to be more resource-intensive.
Factors to Consider
Certain factors, such as the availability of domain-specific data, the tolerance for uncertainty in results, and the willingness to invest in computational power, should heavily influence the choice between these two approaches.
Conclusion
In navigating the complex terrain of domain knowledge incorporation in language models, our journey is one of constant assessment and adaptation. Both fine-tuning and RAG represent leading strategies, each replete with strengths and trade-offs. While there may be no one-size-fits-all answer, the key to unlocking the potential of AI systems lies in understanding and consciously selecting the tool that best suits the task at hand.
As we stride forward, it’s clear that a balanced approach, perhaps even a hybrid of fine-tuning and RAG, could be the most promising direction. It’s incumbent upon us as practitioners to continue probing, experimenting, and pushing the boundaries of what is possible with language models. By doing so, we will not only elevate the efficiency of our AI systems but also deepen our understanding of what it truly means to teach machines with human wisdom.
Investing in the right approach isn’t just about model performance; it’s about the ethical and practical implications of the choices we make in the burgeoning field of AI. The confluence of domain knowledge and language models is a domain ripe with potential, and as we integrate these methods into our systems, it will be exciting to see how they unfold, bringing us discoveries, better performance, and perhaps most importantly, a greater appreciation for the delicate art of AI model construction.
Categories: Thought Leadership


{kind=link}